
Introduction to Predictive Analytics
Predictive analytics is a branch of data analysis that focuses on predicting future outcomes based on historical data. By leveraging statistical algorithms and machine learning techniques, organizations can analyze current and historical data to identify trends, assess probabilities, and make informed decisions. Unlike traditional analytics, which primarily describes past events or provides insights into current situations, predictive analytics takes a forward-looking approach that enables businesses to anticipate potential challenges and opportunities.
The primary objective of predictive analytics is to provide organizations with actionable insights by forecasting future events with a high degree of accuracy. This process involves utilizing advanced computational techniques, such as artificial intelligence (AI) models and machine learning algorithms, which enhance the analysis of large datasets. As these technologies continue to evolve, they play a critical role in improving the reliability and precision of predictive models.
Key concepts associated with predictive analytics include data mining, statistical modeling, and machine learning. Data mining involves extracting patterns and knowledge from vast sets of data, while statistical modeling provides a framework to understand relationships within that data. Machine learning, a subset of AI, enables computers to learn from data, identify complex patterns, and improve predictions over time without requiring explicit programming for each outcome.
Ultimately, the integration of AI and machine learning into predictive analytics empowers organizations to make data-driven decisions that can improve operational efficiency, enhance customer experiences, and optimize resource allocation. As businesses increasingly rely on advanced analytical methods, understanding the nuances of predictive analytics becomes essential for leveraging these powerful forecasting tools effectively.
The Role of AI in Predictive Analytics
Artificial Intelligence (AI) has fundamentally transformed the landscape of predictive analytics, optimizing the capacity to process vast amounts of data and derive actionable insights. By integrating advanced machine learning algorithms, AI enhances the predictive accuracy and efficiency of analytics systems. These AI models are designed to identify patterns within complex data sets, allowing organizations to make data-driven decisions with greater confidence.
One of the primary benefits of employing AI in predictive analytics is its ability to learn from historical data. Machine learning algorithms can analyze past trends and user behaviors, improving their predictions over time. For instance, retail companies utilize AI-driven predictive models to analyze customer purchasing patterns and optimize inventory management. By predicting which products are likely to sell, retailers can minimize stockouts and reduce excess inventory, which in turn maximizes profitability.
Similarly, in the financial sector, AI plays a pivotal role in risk assessment. Financial institutions leverage predictive models powered by AI to evaluate the potential for loan default by analyzing a multitude of variables, including market trends, borrower history, and economic indicators. This integration not only speeds up the decision-making process but also enhances accuracy by uncovering hidden correlations that traditional methods might overlook.
Healthcare is another industry experiencing profound transformations due to AI in predictive analytics. Machine learning algorithms are utilized to forecast patient outcomes, enabling healthcare providers to tailor preventive measures and interventions effectively. For example, predictive models can help in identifying patients at risk of developing chronic diseases, allowing for timely interventions that improve patient care and reduce overall healthcare costs.
As organizations continue to harness the capabilities of AI within predictive analytics, the potential for enhanced decision-making across various industries grows ever more promising. The synergy between AI and analytics not only optimizes existing processes but also opens new avenues for innovation and strategic growth.
Understanding Machine Learning: Types and Techniques
Machine learning, a subset of artificial intelligence, is fundamentally about teaching computers to learn from data and make predictions or decisions without being explicitly programmed. This technology plays a crucial role in predictive analytics, offering different methodologies that cater to various analytical needs. The primary types of machine learning are supervised learning, unsupervised learning, and reinforcement learning, each distinguished by its learning process and application domain.
Supervised learning involves training a model on a labeled dataset, where the input data is paired with corresponding output labels. The model learns to map inputs to outputs, making it ideal for prediction tasks where historical data exists. Common algorithms in supervised learning include linear regression, decision trees, and support vector machines. These techniques are particularly effective for classification and regression problems, providing accurate predictions based on past observations.
In contrast, unsupervised learning deals with unlabeled data, aiming to uncover hidden patterns or intrinsic structures within the dataset. By analyzing the relationships and groupings of data points, unsupervised learning techniques such as clustering and dimensionality reduction can identify trends and insights without prior knowledge of outcomes. Applications of unsupervised learning are prevalent in customer segmentation and anomaly detection, where understanding the underlying structure of data is crucial.
Reinforcement learning differs significantly from the aforementioned types, as it is based on the interaction between an agent and its environment. The agent learns to make decisions by receiving feedback in the form of rewards or penalties for its actions, thereby refining its strategy over time. Reinforcement learning algorithms, such as Q-learning and deep Q-networks, have shown remarkable success in complex problem-solving scenarios, such as game playing and robotics.
In the domain of predictive analytics, selecting the appropriate machine learning technique largely depends on the nature of the data and the specific objectives of the analysis. By understanding these fundamental types and techniques, organizations can better harness the power of machine learning to enhance their predictive capabilities.
Data Collection and Preparation for Predictive Analytics
Data collection and preparation form the backbone of any predictive analytics endeavor. High-quality data is essential as it directly influences the accuracy and reliability of predictions derived from machine learning algorithms. To begin with, organizations must establish clear objectives that define the scope of the predictive analysis. With specific goals in mind, data collection can be tailored to ensure that relevant data is obtained.
During the data collection phase, it is important to leverage various sources, including internal databases, external APIs, and web scraping. Each of these sources can provide valuable insights, but they must also be evaluated for quality and relevance. Data collected should encompass a wide range of variables pertinent to the predictive model to foster comprehensive analysis. Incorporating diverse datasets can enrich the predictive power by providing multiple perspectives on the same problem.
Once the data is collected, the next vital step involves cleaning and organizing the information. Data cleaning entails identifying and rectifying anomalies or inconsistencies that may skew the analysis, such as missing values, duplicates, or incorrect entries. Techniques such as imputation can be used to handle missing data effectively by replacing it with statistical estimates based on the surrounding values. Furthermore, regularizing the data into a unified format enhances consistency, enabling better model performance.
After cleaning, data should be organized logically into structured formats suitable for analysis. Effective data formatting facilitates seamless integration into machine learning algorithms, ultimately leading to more accurate predictions. Additionally, creating metadata can provide context to the data, allowing analysts to understand its source, limitations, and potential implications when interpreting the results. By adhering to these best practices, organizations can significantly improve their predictive analytics outcomes.
Building Predictive Models: Step-by-Step Guide
Constructing predictive models is a fundamental aspect of leveraging AI and machine learning in predictive analytics. The first step is selecting the appropriate algorithm, which depends on the type of data and the specific problem to be addressed. Commonly employed algorithms include linear regression for continuous outcomes, decision trees for classification, and support vector machines for complex datasets. Understanding the strengths and weaknesses of each algorithm is crucial in making an informed decision.
Once the algorithm has been selected, the next phase involves training the model. This process typically requires a labeled dataset, which is used to teach the model to recognize patterns. Data preprocessing is an essential part of this step; it may involve cleaning the data, handling missing values, and normalizing or scaling features. The quality of the data directly affects the model’s performance, making thorough preprocessing vital.
After training the model, validating its performance is critical. Techniques such as cross-validation can help assess the model’s accuracy by dividing the dataset into training and testing sets. This division allows for an unbiased evaluation of how the model may perform on unseen data. It’s recommended to use multiple metrics, such as accuracy, precision, recall, and F1-score, to ensure a comprehensive assessment of model performance.
Tuning hyperparameters is another important step in optimizing model performance. This involves adjusting the settings of the algorithm to improve predictions. Techniques like grid search or random search can be employed to identify the best hyperparameter combinations. Care must be taken to avoid common pitfalls, such as overfitting, where the model performs well on training data but poorly on new data.
By carefully navigating these steps, practitioners can build robust predictive models that leverage the full potential of AI and machine learning in predictive analytics.
Evaluating Predictive Model Performance
Evaluating the performance of predictive models is a critical step in ensuring that they meet the necessary standards for accuracy and reliability. Various metrics can be utilized to assess the effectiveness of these models, helping data scientists and analysts make informed decisions. One fundamental tool for evaluation is the confusion matrix, which is a comprehensive table that visualizes the performance of a classification model by detailing true positives, false positives, true negatives, and false negatives. This matrix not only provides insight into the model’s overall predictive accuracy but also highlights areas requiring improvement.
Another key concept in evaluating predictive models is precision, which measures the proportion of true positive outcomes relative to the total number of positive predictions. High precision indicates the model’s ability to minimize false positives, making it particularly valuable in contexts where the cost of false alarms is high. Complementarily, recall, or sensitivity, assesses the model’s ability to correctly identify all relevant instances. A model with high recall captures most of the true positives, although it may also produce a greater number of false positives.
The F1 score provides a harmonious balance between precision and recall, measuring their weighted average. This metric is especially useful in situations where there is an uneven class distribution, ensuring that both false positives and false negatives are given due consideration in model evaluation. Additionally, the ROC-AUC (Receiver Operating Characteristic – Area Under Curve) metric is instrumental in evaluating the trade-off between true positive rates and false positive rates across various threshold settings. The ROC-AUC value ranges from 0 to 1, with a score closer to 1 signaling optimal model performance.
Overall, a comprehensive evaluation strategy that incorporates these metrics allows for a nuanced understanding of predictive model performance, enabling practitioners to refine and optimize their predictive analytics efforts.
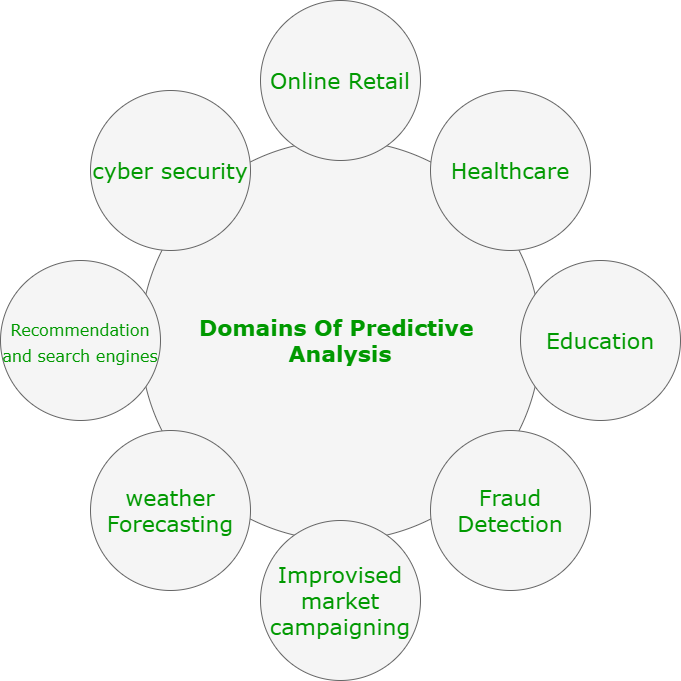
Applications of Predictive Analytics Across Industries
Predictive analytics has emerged as a transformative tool in various sectors, leveraging the power of artificial intelligence and machine learning to unveil actionable insights from data. In healthcare, predictive analytics is applied to patient care through tools that analyze historical patient data, enabling providers to anticipate patient needs, optimize treatment plans, and even forecast the prevalence of diseases. For instance, hospitals use machine learning algorithms to identify high-risk patients based on their medical history, which allows for proactive interventions that can improve patient outcomes and reduce healthcare costs.
In the finance sector, organizations utilize predictive analytics to enhance risk assessment and fraud detection. Financial institutions employ sophisticated algorithms to analyze transaction data, recognize patterns, and flag unusual behavior indicative of fraud. Machine learning models can predict credit risk more accurately, allowing lenders to make informed decisions about loan approvals and terms. A significant case study highlights how a leading bank implemented predictive modeling to reduce default rates by tailoring loan products to customer profiles, ultimately improving profitability.
The retail industry also benefits significantly from predictive analytics. Retailers analyze consumer behavior, sales trends, and inventory levels to optimize supply chains and enhance customer experiences. For example, a major retail chain utilized predictive analytics to manage inventory more efficiently, thereby reducing waste and lowering costs while ensuring that popular products are always in stock. This case demonstrated how data-driven decisions lead to improved customer satisfaction and increased sales.
Manufacturing industries harness predictive analytics to anticipate equipment failures and optimize maintenance schedules. By employing machine learning algorithms to analyze sensor data from machines, manufacturers can predict when maintenance should occur, thereby minimizing downtime and extending equipment lifespan. This proactive approach allows companies to save costs associated with unscheduled repairs while maintaining operational efficiency.
Across these diverse applications, the integration of AI and machine learning into predictive analytics demonstrates its potential to fundamentally reshape industries by driving better decision-making and operational efficiencies.
Challenges and Limitations in Predictive Analytics
While predictive analytics offers significant advantages to organizations striving for data-driven decision-making, several challenges must be addressed for effective implementation. One of the foremost concerns is data privacy. With an increasing reliance on vast datasets, organizations must navigate legal regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). These regulations impose strict guidelines on the storage and processing of personal information, posing a risk of non-compliance that could lead to heavy fines and damage to reputation. Therefore, it is crucial for organizations to establish robust data governance frameworks to protect consumer data while harnessing its potential for predictive insights.
Another critical challenge is algorithm bias, whereby the predictive models may reflect societal biases present in the training data. This can lead to unfair or inaccurate outcomes, especially in sensitive areas such as hiring, lending, and criminal justice. Organizations should employ practices such as diverse data sourcing and algorithm auditing to identify and mitigate bias in predictive analytics. By consciously reviewing the datasets and models, businesses can enhance fairness and accuracy in their predictions.
Moreover, the complexities surrounding model maintenance cannot be overlooked. Predictive models require regular updates and recalibration to remain relevant in changing environments. As new data becomes available, organizations must invest in continuous training of models, ensuring they adapt to trends, seasonality, and anomalies. Automated retraining processes and model monitoring systems can help ease this burden, enabling organizations to maintain the robustness of their predictive analytics efforts.
In conclusion, although predictive analytics presents numerous opportunities, organizations must be vigilant in addressing challenges related to data privacy, algorithm bias, and model maintenance. By proactively developing strategies to overcome these limitations, businesses can leverage predictive analytics to drive innovation and enhance decision-making capabilities effectively.
Future Trends in AI and Machine Learning for Predictive Analytics
The landscape of predictive analytics is rapidly evolving, driven primarily by advancements in artificial intelligence (AI) and machine learning. One notable trend is the continuous enhancement of deep learning techniques. These methods are becoming more sophisticated, allowing for more complex data analysis and enabling predictive models to achieve unprecedented levels of accuracy. Deep learning is particularly effective in processing unstructured data, such as images and text, which are increasingly important in various sectors, including healthcare, finance, and marketing.
Another significant trend is the emergence of automated machine learning, commonly referred to as AutoML. AutoML simplifies the model-building process by automating repetitive tasks traditionally performed by data scientists. This democratization of machine learning allows non-experts to create and fine-tune predictive models, effectively broadening the user base and accelerating the adoption of predictive analytics across different industries. As AutoML technologies continue to develop, we can expect a surge in both the accessibility and implementation of machine learning solutions.
Additionally, the ethical considerations surrounding AI and machine learning are gaining prominence. As organizations increasingly rely on predictive analytics, questions about data privacy, bias, and accountability become critical. Developers and businesses are now urged to incorporate ethical frameworks into their machine learning practices to ensure fairness and transparency. This shift towards ethical AI is becoming a necessity, aiming to build trust with users and stakeholders in predictive analytics systems.
Lastly, the integration of AI with the Internet of Things (IoT) devices presents a transformative opportunity for predictive analytics. With IoT generating vast amounts of real-time data, the potential for AI-powered predictive models to analyze and act upon this information will be a game changer. As these technologies continue to converge, the ability to make informed, timely decisions based on predictive analytics will enhance operational efficiencies across diverse sectors.
Leave a Reply